


Machine Learning: A Gentle Introduction

Machine Learning is undeniably one of the most influential and powerful technologies in today’s world. More importantly, we are far from seeing its full potential. There’s no doubt, it will continue to be making headlines for the foreseeable future.
We have seen Machine Learning as a buzzword for the past few years, the reason for this might be the high amount of data production by applications, the increase of computation power in the past few years and the development of better algorithms.
History of Machine Learning
The locution Machine Learning was coined by Arthur Samuel in 1959, an American pioneer in the field of computer gaming and artificial intelligence and stated that “it gives computers the ability to learn without being explicitly programmed”. And in 1997, Tom Mitchell gave a “well-posed” mathematical and relational definition that “A computer program is said to learn from experience E concerning some task T and some performance measure M, if its performance on T, as measured by M, improves with experience E.
The formal definition of Machine Learning
It’s impossible to define Machine Learning using some sets of words to a beginner. But Let’s try to define it:
Machine learning is the science of getting computers to act without being explicitly programmed.
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
In the past decade, machine learning has been used for the development of various things like self-driving cars, practical speech recognition, effective web search, a wearable fitness tracker like Fitbit, or an intelligent home assistant like Google Home and a vastly improved understanding of the human genome. Machine learning is so widespread today that even you use it dozens of times a day without knowing it.
There are many more examples of ML in use.
- Prediction — Machine learning can also be used in the prediction systems as well. Let’s consider the loan example, for computing the probability of a fault, a system will be needed to classify the available data in groups.
- Image recognition — Machine learning can be even used for face detection in an image. There is a different category for each person in a database of several people.
- Speech Recognition — It is the translation of spoken words into the text. It is used in voice searches and more. Voice user interfaces include voice dialing, call routing, and appliance control. It can also be used as simple data entry and the preparation of structured documents.
- Medical diagnoses — ML is trained to recognize cancerous tissues.
- The financial industry and trading — companies use ML in fraud investigations and credit checks.
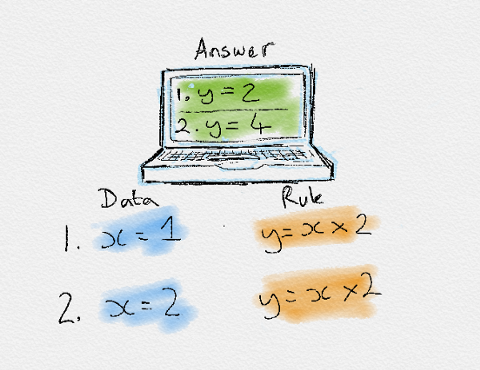
Traditionally, software engineering has combined human-created rules with data to create answers to a problem, instead of that, machine learning uses data and answers to discover the rules behind a problem. (Chollet, 2017)

Let’s talk about different types of Machine Learning techniques or algorithms used in modern Technology World.
Different Categories of Machine Learning Algorithms
Machine Learning algorithms are majorly classified as the following categories:
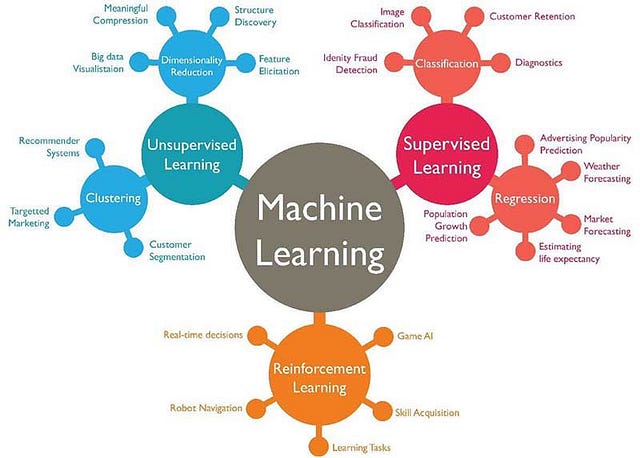
- Supervised learning — When an algorithm learns from given example data and their associated target responses that will consist of numeric values or string labels, such as classes or tags, to later predict the correct response for new data, this type of algorithm comes under the category Supervised learning. This approach is as expected similar to human learning under the supervision of a teacher. For example, our teacher taught us about Fruits, Vegetables, Plants, etc in our Childhood. In this way only we teach ML algorithms in this category.
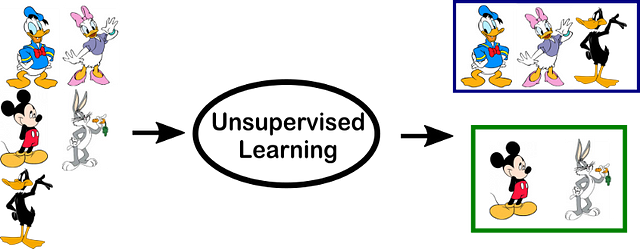
- Unsupervised learning — When an algorithm learns from plain examples without any associated response or labels, leaving it to the algorithm to determine the data patterns present in data, on its own. This type of algorithm tends to restructure the data into something else, such as new features that may represent a class or a new series of un-correlated values. For example, as we do in real life like defining things by giving some reasons or rules. Some recommendation systems which you find on the web in the form of marketing automation are based on this type of learning.
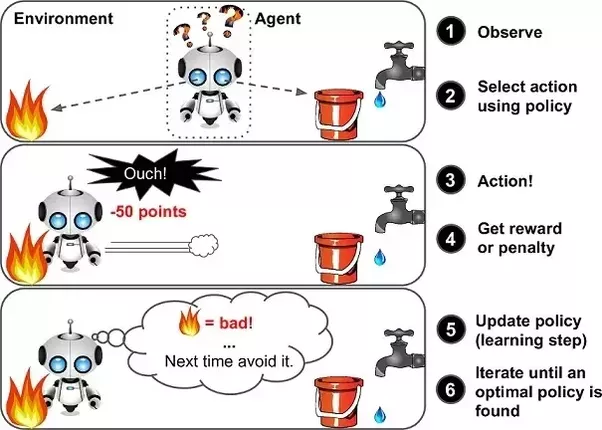
- Reinforcement learning — When you present the algorithm with examples that lack labels, as in unsupervised learning. However, you can take an example with positive or negative feedback whichever according to the solution, the algorithm proposes comes under the category of Reinforcement learning, which is connected to applications for which the algorithm must make decisions (so the product is prescriptive, not just descriptive, as in unsupervised learning), and the decisions bear consequences. In this human world, it is just like learning by trial and error.
Errors will help you in learning because they have a penalty added (cost, loss of time, regret, pain, and so on), teaching you that a certain course of action is less likely to succeed than others. An interesting example of reinforcement learning is when a computer learns to play video games by themselves.
In this case, where an application presents the algorithm with examples of specific situations, such as having the gamer stuck in a maze while avoiding an enemy. There are many chances of new development in Reinforcement learning as compared to other learning.
Types of Machine Learning algorithms based on Output
Another classification of machine learning tasks arises when one considers the desired output of a machine-learned system:
- Classification: When inputs are classified into two or more than two classes, and the learner must produce a model that assigns unseen inputs to one or more (multi-label classification) of these classes. This is typically tackled in a supervised way. Spam filtering is the best example for classification, where the inputs are email (or other) messages and the classes are “spam” and “not spam”.
- Regression: Which is also a supervised problem, A case when the outputs are continuous rather than discrete.
- Clustering: When a set of inputs is to be divided into groups. Far from classification, the groups are not known beforehand, making this typically an unsupervised task.
Machine Learning comes into the picture when problems cannot be solved through common approaches.
Useful Machine Learning Terminologies
- Dataset: A set of data examples, that contain features important to solving the problem.
- Features: Important pieces of data that help us understand a problem. These are fed into a Machine Learning algorithm to help it learn.
- Model: The representation (internal model) of a phenomenon that a Machine Learning algorithm has learned. It learns this from the data which is shown during training. The model is the output of an algorithm after training with examples. For example, a decision tree algorithm would be trained and after training, it will produce a decision tree model.
- Training data
Training data is used to train a model. It means that the ML model sees that data and learns to detect patterns or determine which features are most important during prediction. - Validation data
Validation data is used for tuning model parameters and comparing different models to determine the best one for our dataset. The validation data should be different from the training data, and should not be used in the training phase. Otherwise, the model would overfit, and poorly generalize to the new (production) data. - Test data
It may seem tedious, but there is always a third, final test set (also often called a hold-out). It is used once the final model is chosen to simulate the model’s behavior on a completely unseen data, i.e. data points that weren’t used in building models or even in deciding which model to choose. - Overfitting
It’s a negative effect when the model builds an assumption — bias — from an insufficient amount of data. When overfitting happens, it usually means that the model is treating random noise in the data as a significant signal and adjusts to it, which is why it degenerates on a new data (as the noise present over there can be different). This is generally the case in very complex models like Neural Networks or Gradient Boosting. - Training
The process of training an ML model involves providing an ML algorithm (that is, the learning algorithm) with training data to learn from. The term ML model refers to the model afterimage that is created by the training process. - Prediction
After training our ML model, we tend to get the output w.r.t some values of features that may be unknown for a model. After feeding those values to the model, the model predicts the output based on rules learned by the model during training.
Some Machine Learning Algorithms
Linear Regression
Linear regression is a type of linear approach for modeling a direct relationship between a variable response (also known as dependent variable) and one or more explanatory variables (also known as independent variables). The case of one explanatory variable is called simple linear regression. For more than one explanatory variable, the process is known as multiple linear regression. This phrase is distinct from multivariate linear regression, where multiple correlated dependent variables or multiple outputs are predicted, rather than a single scalar variable or a single output.
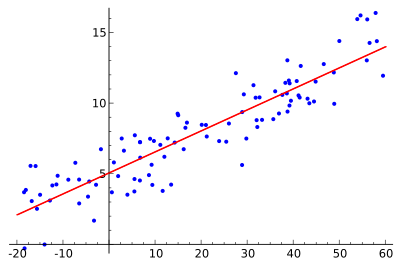
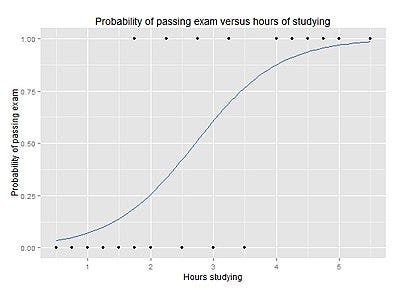
Logistic Regression
The logistic model (also known as the logit model) is a widely used statistical model that in its basic form uses a logistic function to model a binary dependent variable, although many more complex extensions exist. In regression analysis, logistic regression (or logit regression) is used for estimating the parameters of a logistic model (a form of binary regression). Mathematically, a binary logistic model has a dependent variable with two possible values, such as pass/fail, win/lose, alive/dead or healthy/sick; these are represented by an indicator variable, where the two values are labeled “0” and “1”.
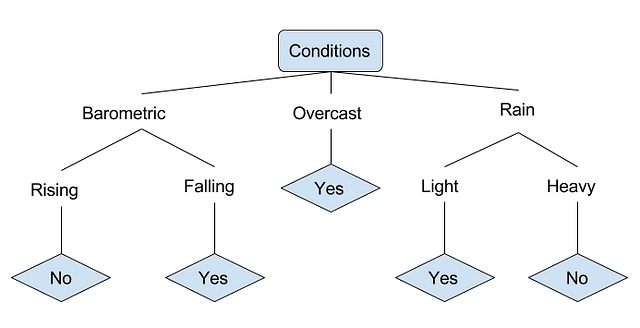
Decision Tree Learning
Generally, decision trees are employed to visually represent decisions and show or inform decision making. When working with machine learning or data mining, decision trees are used as a predictive model. These models outline observations about data to conclusions about the data’s target value.
In these predictive models, the data’s features that are determined through observation are represented by the branches, while the conclusions about the data’s target value are represented as leaves.
Let’s look at an example of various conditions that can determine whether or not someone should go fishing outside. This includes weather conditions and barometric pressure conditions.
k-Nearest Neighbor
The k-nearest neighbor algorithm is a pattern recognition model that can be used for classification as well as for regression. Often abbreviated as k-NN, the k in the k-nearest neighbor is a positive integer, which is typically small. In either classification or regression, the input will consist of the k nearest training examples within a space.
We will focus on k-NN classification. In this method, the output is class membership. This will assign a new object to the class to which its majority of k nearest neighbor belongs. In the case of k = 1, the object is assigned to the class of the nearest neighbor.
Let’s look at an example of a k-nearest neighbor. In the given below diagram, there are blue diamond objects and orange star objects. These belong to two separate classes i.e. the diamond class and the star class.

YaY..!! 👻 You’re almost done. Now, you have basic terminologies of Machine Learning.
For videos with exercises on Data Analysis and Python, check out HERE.
Originally post on enappd.com on June 18, 2019